情報の教科書に「データを表で表すものがリレーショナルデータベースである」と書いてあるものがあり、とてもびっくりしました。この定義では表計算ソフトもリレーショナルデータベースを扱っていることになってしまいます。データベースに初めて触れる人も疑問に思うはずです。
1980年代、まだWindowsがなかった時代に dBASE Ⅲ というソフトウェアが販売されていて、「リレーショナルデータベース」であることを売り物にしていました。R-BASE という対抗ソフトも出てこれも「リレーショナルデータベース」であることを標榜していました。それに対して「リレーショナルデータベース」でないデータベースは、日本では「カード型データベース」と呼ばれていました。
「リレーショナルデータベース」を謳う製品は高価で使い方も難しそうだったのでほとんど触ったことはありませんでしたが、それでも雑誌の記事などで盛んに特集されていて、カード型データベースとの違いを読んで知っていましたから、ただの表がリレーショナルデータベースだというのは、とんでもない間違いだと直感したわけです。
カード型データベースはコンピュータ以前に使われていたカードをコンピュータ化したものです。たとえば図書館の蔵書カードは書名、著者名、発行年月日、出版社、分類番号、大きさ、ページ数といったデータが1冊の本ごとに1枚つくられます。1枚のカードのデータを表計算の1行に対応させれば表になります。これも表を使うのでリレーショナルデータベースだというのなら、カード型データベースとの区別が成り立ちません。
ウィキペディアでは(2013年3月現在)、「関係モデル(リレーショナルデータモデル、後述)にもとづいて設計、開発されるデータベースである」とあります。この後述を見てもリレーショナルデータモデルがなかなかわかりにくい。
「関係モデル」の説明で表に表せるような関係をリレーションと呼ぶと書いてあったりするので、「だからリレーショナルデータベースと言うのか」と納得してしまったものだと思います。dBASE Ⅲ の標榜していた「リレーショナル」は表同士のリレーションのことでした。
この誤解はかなり蔓延していて、IT用語辞典 e-Words (e-words.jp)でも「リレーショナルデータモデルの理論に従っている。1件のデータを複数の項目(フィールド)の集合として表現し、データの集合をテーブルと呼ばれる表で表す方式。」と書いてあります。これは1枚の表そのものですね。
「複数の表から結合演算ができるデータベースがリレーショナルデータベース」という理解の仕方が妥当と思います。もちろん「結合演算」は複数の表を関連付けてデータを自由に取り出せる仕組みなどと噛み砕いた言い方をしてもいいでしょう。
表計算ソフトとの違いを理解して目的に合わせて使い分けるための知識を持つことが大切です。表計算でもlookup関数などで表の関連付けができますが、限界がありますし効率も悪くなります。逆にリレーショナルデータベースを表計算感覚で使ってしまえばその能力を発揮させることはできません。
リレーショナルデータベースに触れるならば少なくとも複数の表を関連付けて必要なデータを取り出せるように設計することまで理解させるわけですから、リレーショナルデータベースとはなにかという説明もそれに沿ったものであるべきでしょう。
ウィキペディアの関係モデルの説明に「データは表に似た構造で管理され、複数のデータ群が関係(リレーション)と呼ばれる構造で相互連結可能である。」とあります。表に似ているけど表ではないと読めます。また複数の表でなく複数のデータ群と表現して「表」を避けています。
「表に似ているけど表ではない」と言うと、何か条件が足りないように感じてしまいますが逆です。条件を加えないと表にできません。それは行の順序と列の順序です。本来は含まれていない行と列の順序を加えることで表に書き表すことができるのです。
というわけで、「データを表で表すものがリレーショナルデータベースである」という言い方はさらに間違っていることになります。順序をつけてはいけないという理由で表で表せないものもリレーショナルデータベースといえるわけですから。
本文で、『「リレーショナルデータベースはデータを表形式で表す」はぎりぎり間違ってはいない。』と書きましたがこれも厳密には間違っていることになりますね。
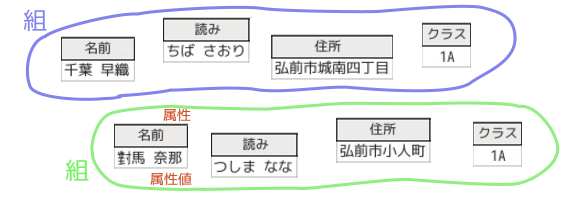
言葉遣いも組(行に相当)、属性(列に相当)といいます。表ではないのでこれは理解できます。
(本文では教科書に合わせて「タプル」と書きましたが、ここでは属性に合わせて組とします)
組と属性での説明は説明図が場所をとってしまいますが、なんとか書けます。問題は表に代わるわかりやすい言葉がないことです。関係というのは組の中ですでに複数の関係があるように見え、組の集合の間にもリレーションという関係があります。データ群ではあまりにも漠然としています。
表(テーブル)という言葉がとても的確です。表で説明するなら要素の名前も「行」と「列」が自然です。
列も行も選択や並べ替えによって自由に変えられることを理解すれば順序が付いているように見えてもさほど大きな問題ではないでしょう。
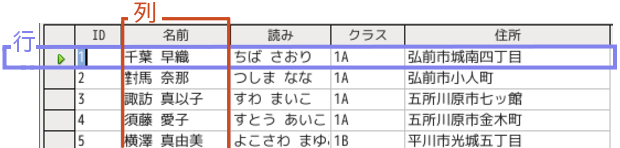
行と列にはレコードとフィールドという言い方もあります。
フロッピーディスクやハードディスクは、ブロック型デバイスと呼ばれます。それはセクタと呼ばれる大きさの決まった単位ごとに読み書きが行われるからです。そこで、データベースも1つのセクタにひと組(1行)のデータを書いていくのが効率が良かったのです。これをレコードと呼びました。記録の単位だったからです。
そして1つのセクタをどのように分けてそれぞれの属性(列・項目)を詰め込んでいくかを決めました。これをフィールドと呼びました。私の頭には所有者や作物の種類ごとに区画された畑が思い浮かびます。

このようにレコードとフィールドという呼び名は記憶装置の構造上の都合から使われるようになったものでしょう。
その後ディスクの容量は飛躍的に大きくなりデータの転送速度も上がりました。読み書きの単位もセクタではなくいくつかのセクタをまとめて読み書きするようになり、セクタの大きさも最近大きくなりつつあります。データベースの方も可変長の文字列を扱えるようになるなど固定長のフィールドのイメージは合わなくなってきています。
リレーショナルデータベースを操作する言語であるSQLは、表、列やテーブル、フィールドの用語を使います。
SELECT "フィールド名" FROM "テーブル名"
と言った具合です
SQLの説明を組や属性で統一するのでなければ、表、列やテーブル、フィールドの混在で初心者に優しくない状況をさらに悪化させることになります。
「組、(行、レコード)」と「属性、(列、フィールド)」という説明も、「行、(レコード、組)」と「列、(フィールド、属性)」とするのが適当ではなかったかと思います。
聖愛中学高等学校