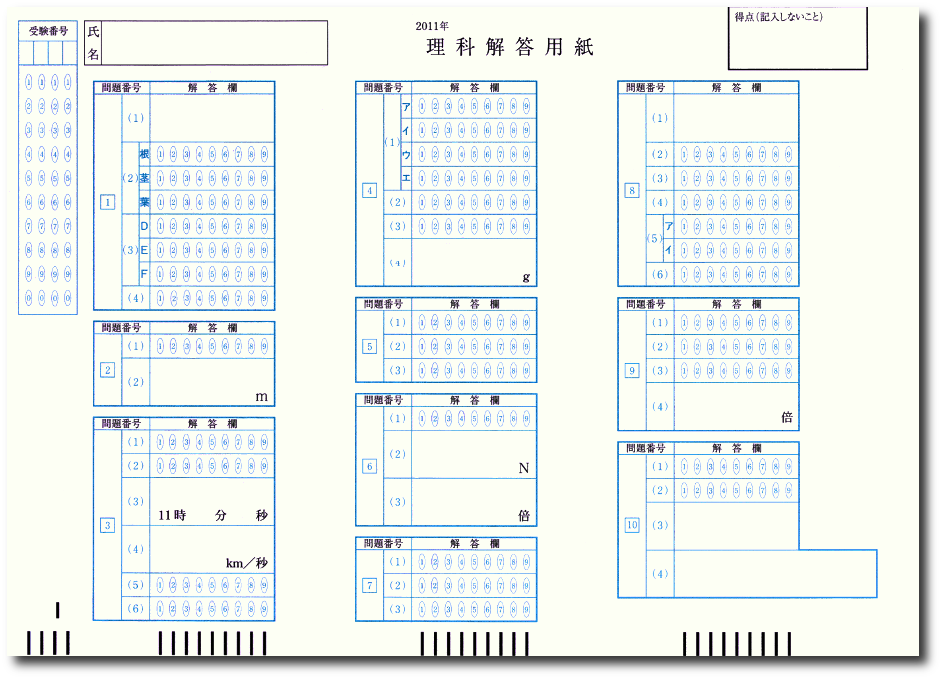
Eコマンドで得られるデータにあるようにマークリーダから送られるデータは欄ごとで、下図の様に横長に使ったときには縦一列を読んだデータを列ごとに読み出すことになります。これを解答欄ごとのデータに変換しなければなりません。
特に入試では通し番号の汎用解答シートを使うのを避け、大問1の問1とか(1)などで解答位置を指定していますから、教科により年度によりレイアウトが異なります。
これをどのようにプログラムに伝えるか。これを解説します。
2011年の理科の解答用紙です。この年はまだSR-505で、0.3インチピッチでしたから24行までで行のマークもA-Wでしめされていましたが、無理やり0.25インチピッチのつもりで0-9,:;<=>?@,A-Gまでの24行として考えてみます。(ほんとうはGまでではなくPまでの33行)
シート 読み取り範囲 対応する解答
[読み取り範囲]をクリックすると読み取る位置とその位置を表すコードが見えます。
[対応する解答]をクリックするとそのコードに対応する解答が見えます。これを以下の様なテキストファイルで指示します。
NNNN IIIIIIIII IIIIIIIII IIIIIIIII
1111
2222 123456789
3333 123456789
4444 123456789 123456789 123456789
5555 123456789 123456789 123456789
6666 123456789 123456789 123456789
7777 123456789 123456789 123456789
8888 123456789 123456789
9999 123456789 123456789
0000 123456789
123456789 123456789
123456789 123456789 123456789
123456789 123456789
123456789
123456789
123456789 123456789
123456789
123456789
123456789 123456789
123456789 123456789
NNNN IIIII は欄をグループ分けする仕組みです。スペースがグループの区切り、Nのついた欄は受験番号のフィールド、Iのついた欄はは解答のフィールドを表しています。最下行のタイミングマークに対応します。ただしマークリーダーはタイミングマークの間が余計に間が空いていることは関知しません。そこで4欄と5欄の間に区切りがあることをNNNN IIII... のスペースで知らせるわけです。
その次の行からはそこにマークを感知したとき何を選んだことになるかの記号を書きます。たとえば
1,2,3,4欄の F にマークがあった場合は、それぞれ 1111 5,6,7,8,9,10,11,12,13欄の C にマークがあった場合は、それぞれ 123456789
とマークがあったとするということです。文字がなくスペースの所はマークがあっても無視するところになります。
マークシートを正値したときのレイアウトを、そのままテキストファイルにすればよいようにしています。
上記のファイルを文字変数の配列DS$(i)に読みます。まず1行目の"NNNN IIIII...."がDS$(0)に読み込まれたとしてそれを切り分けます。
DEFINT A-Z
TRUE=(1=1):FALSE=NOT TRUE
DS$(0)="NNNN III IIIII IIIIIIII IIIIIIII"
' == *SETCODE の一部 ==
DIM CMBG(80),CMW(20),PTR(80)
CMON=FALSE:CMMX=0:CM=0:TMCT=0:WCT=0
FOR I=1 TO LEN(DS$(0))
I$=MID$(DS$(0),I,1)
IF I$<>" " THEN
TMCT=TMCT+1:PTR(TMCT)=I
IF CMON=FALSE THEN
CM=CM+1:CMBG(CM)=TMCT:WCT=1
CMON=TRUE
IF I$="N" THEN CMJUB=CM
ELSE
WCT=WCT+1
ENDIF
ELSE
IF CMON=TRUE THEN CMW(CM)=WCT:CMON=FALSE
ENDIF
NEXT
CMW(CM)=WCT:CMON=FALSE:CMMX=CM:IDCM=CMW(CMJUB)
このプログラムで次のようなデータが用意されます。このBASICでも配列の添字は0からですが、ここでは1から使用しています。
CMMX=5 TMCT=28 CMJUB=1 CMBG(1)= 1 CMW(1)=4 CMBG(2)= 5 CMW(2)=3 CMBG(3)= 8 CMW(3)=5 CMBG(4)=13 CMW(4)=8 CMBG(5)=21 CMW(5)=8 PTR(i)=0,1,2,3,4,6,7,8,10,11,12,13,14,16,17,18,19,20,21,22,23,25,26,27,28,29,30,31,32 DS$(0)="NNNN IIIIIIIII II..." DS$(g)="3333 123456789 12..."
各変数の説明です。
PTR(i) :DS$(0)のうちスペースでない文字の位置を表す
"NNNN IIII III" なら 1,2,3,4,6,7,8,9,11,12,13
CMBG(i):i番目のコラム(Tマークの群)が始まるTマークの番号を表す
"NNNN IIII III" なら 1,5,9
(Tマークには隙間はないのでNNNNIIIIIIIと読んでいる)
CMW(i) :i番目のコラム(Tマークの群)の幅(Tマーク数)を表す
"NNNN IIII III" なら 4,4,3
CMMX :コラム数
CMJUB :受験番号になるコラム番号(先頭がNであることで判断)
マークリーダの都合で行単位で読みだしたものを、解答欄ごとに再構成するプログラム。
WHILE と DOITを組み合わせている部分は、N88BASICが IF〜ENDIF(多行IF文) が使えなかったのでその代用の構文。受験番号(CMJUB)以外のグループだけ処理するのに使用している。02とあるのは2002年に国語の受験番号のグループを縦書きに合わせて右に移動したにの対応させたもの。
解答欄ごとに再構成したマークは一旦KA$(i)に収められ、その後使わない解答欄を省いて最終的にSE$(i)に格納する。
*TOMMS 'i(DEK$(),SKA$(),MM()),o(KA$(M)),w(CM,J,I,OTH,MBG,U,SK$,S$)
ERASE KA$:DIM KA$(MLIM) :CMCT=0:DOIT=FALSE
FOR CM=1 TO CMMX 'CM1
IF CM<>CMJUB THEN DOIT=TRUE '<<02
WHILE DOIT
CMCT=CMCT+1
FOR J=1 TO CMW(CM)
AX$=AX$(CMBG(CM)+J-1)
FOR I=1 TO LEN(AX$)
S$=MID$(AX$,I,1)
if S$=" " then continue
U$=MID$(DS$(GYOMX-ASC(S$)+&H30),PTR(CMBG(CM)+J-1),1)
IF U$<>" " THEN M=CMCT*GYOMX-ASC(S$)+&H30:KA$(M)=KA$(M)+U$ 'CM1
NEXT
NEXT
DOIT=FALSE
WEND
NEXT
MMAX=0
FOR M=1 TO CMMX*GYOMX
IF KA$(M)<>"" THEN MMAX=MMAX+1:MM(MMAX)=M:SE$(MMAX)=KA$(M)
'PRINT M;"(";KA$(M);")";"-";
NEXT :PRINT
RETURN
各変数の説明です。
AX$(i) :マークリーダーが行ごとに読んだデータ。
マークのあった欄に対応するアスキー文字が入っている。
可変長データ。
KA$(i):NNNNでないグルーブの数×マークリーダの欄数からなる解答欄ごとのデータ。
欄のグループ指示に対応する文字のないところは空文字列となる。
SE$(i) :KA$(i)から空文字列でないものを取り出して、通し番号をつけたもの。
MM(i) :SE$()がKA$()の何番目に当たるかの数値。SE$(i)=KA$(MM(i))
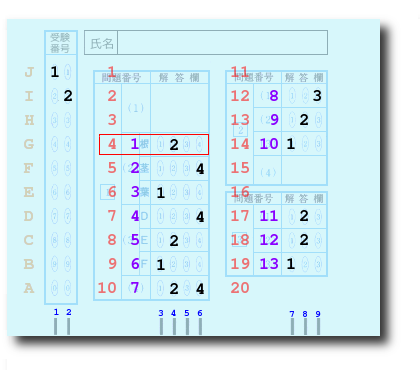
A-Jの10欄からなる架空のマークリーダーとシートを実例に説明してみましょう。
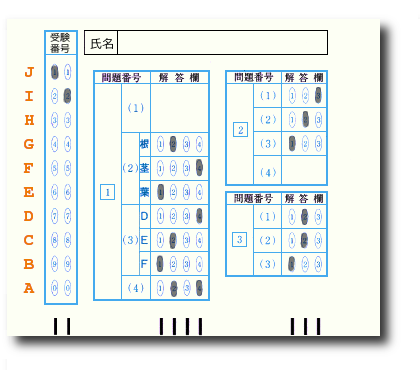 シートはこんな感じで、すでに例としてマークをしてある。レイアウトを指定するテキストファイルは次のようになります。
シートはこんな感じで、すでに例としてマークをしてある。レイアウトを指定するテキストファイルは次のようになります。
NN IIII III 11 22 123 33 123 44 1234 123 55 1234 66 1234 77 1234 123 88 1234 123 99 1234 123 00 1234
これを読んだ後の変数の値は次のようになっています。
CMMX=3 TMCT=9 CMJUB=1 CMBG(1)= 1 CMW(1)=2 CMBG(2)= 3 CMW(2)=4 CMBG(3)= 7 CMW(3)=3 PTR(i)=0,1,2,4,5,6,7,9,10,11 (iは0〜10) DS$(0)="NN IIII III" DS$(1)="11 " DS$(2)="22 123" DS$(3)="33 123" DS$(4)="44 1234 123" DS$(5)="55 1234 " DS$(6)="66 1234 " DS$(7)="77 1234 123" DS$(8)="88 1234 123" DS$(9)="99 1234 123" DS$(10)="00 1234 "
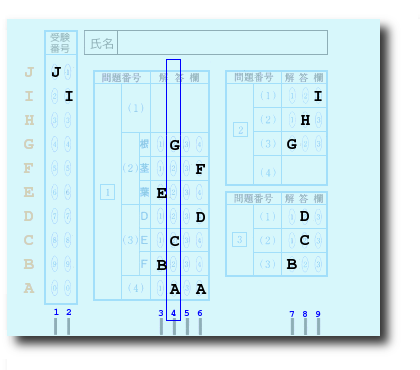 マークリーダのEコマンドで読み取ったデータは次のようになります。
マークリーダのEコマンドで読み取ったデータは次のようになります。
AX$(1)="J" AX$(2)="I" AX$(3)="BE" AX$(4)="ACG" AX$(5)=" " AX$(6)="ADF" AX$(7)="BG" AX$(8)="CDH" AX$(9)="I"
AX$(0)はあえて使っていません。図の下部の青い数字が行番号でAX$()の添字になります。図はAX$(4)が"ACG"であることを示しています。マークリーダの仕様でマークのない行はスペース1個が出力されます(AX$(5))。
また、記述の解答欄への記入や黒い字で印刷された部分も読む場合があります。たとえばAX$(9)では「欄」という字をマークとみなしてAX$(9)="EIJ"となるかもしれません。しかし、レイアウトを指定するテキストではスペースですから次のKA$(M)に影響しません。
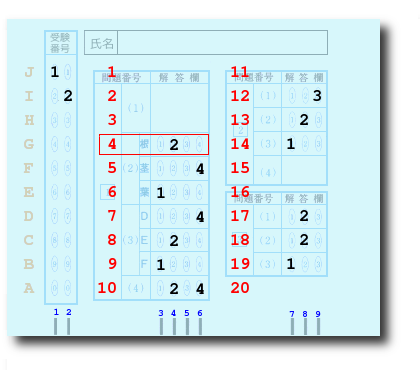 AX$(i)を解答欄ごとに切り出し、さらにA-Jを対応する解答に置き換えます。ます。*TOMMSのサブルーチンで、KA$(M)は次のように変換されます。
AX$(i)を解答欄ごとに切り出し、さらにA-Jを対応する解答に置き換えます。ます。*TOMMSのサブルーチンで、KA$(M)は次のように変換されます。
KA$(1)="" KA$(2)="" KA$(3)="" KA$(4)="2" KA$(5)="4" KA$(6)="1" KA$(7)="4" KA$(8)="2" KA$(9)="1" KA$(10)="24" KA$(11)="" KA$(12)="3" KA$(13)="2" KA$(14)="1" KA$(15)="" KA$(16)="" KA$(17)="2" KA$(18)="2" KA$(19)="1" KA$(20)=""
 さらに*TOMMSのサブルーチンの最後で、使用する解答欄SE$(N)だけを取り出します。
さらに*TOMMSのサブルーチンの最後で、使用する解答欄SE$(N)だけを取り出します。
SE$(1)="2" :MM(1)=4 SE$(2)="4" :MM(2)=5 SE$(3)="1" :MM(3)=6 SE$(4)="4" :MM(4)=7 SE$(5)="2" :MM(5)=8 SE$(6)="1" :MM(6)=9 SE$(7)="24" :MM(7)=10 SE$(8)="3" :MM(8)=12 SE$(9)="2" :MM(9)=13 SE$(10)="1" :MM(10)=14 SE$(11)="2" :MM(11)=17 SE$(12)="2" :MM(12)=18 SE$(13)="1" :MM(13)=19
変数名がSEになっていますが、これは正解のマークとして読み取らせた場合を想定しています。
MM()について追加。KA$()の値をもとにSE$()に正解の設定をするのがここ*TOMMSですが、正解以外のシートではMM()の値に従いKA$()の値を詰めてKA$()をそのまま使います。そのためにMM()の理解が必要です。